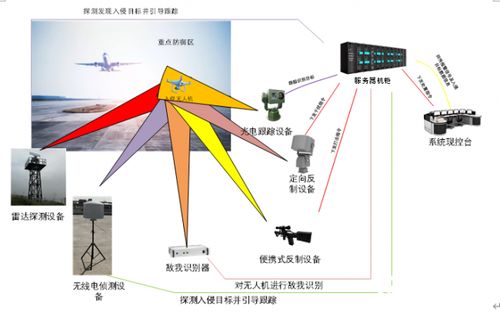
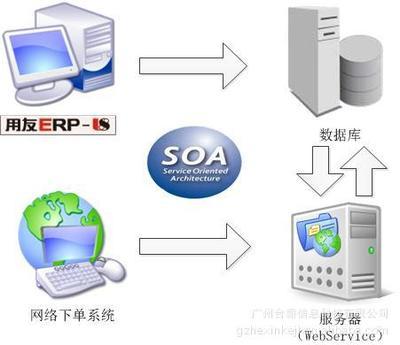
如若轉載,請注明出處:http://m.kwby.net.cn/product/50.html
更新時間:2026-04-09 12:29:10
地址:青海省西寧市城東區湟中路189號12號樓2單元2311室
電話:1869763**
Copyright © 2026 m.kwby.net.cn 信息科技 青海大愚信息科技有限公司 信息科技 版權所有 Sitemap